
Major 3D sensing technologies
Our previous article titled “3D vision systems – which one is right for you?” covered the most important parameters of 3D vision systems, and what are the trade-offs of some parameters being rather high. The discussed parameters included the scanning volume, data acquisition & processing time, resolution, accuracy & precision, robustness, design & connectivity, and the price/performance ratio.
Each of these parameters plays its role in specific applications – where one parameter is key, other can be minor and vice versa.
We will refer to these parameters for a better comparison of the individual technologies behind 3D vision systems and the possibilities they provide.
3D sensing technologies
The technologies powering 3D vision systems can be divided into two major groups. One uses the time of flight principle and the other one the principle of triangulation:
A. Time-of-flight
- Area scan
- LiDAR
B. Triangulation-based methods
- Laser triangulation (or profilometry)
- Photogrammetry
- Stereo vision (passive and active)
- Structured light (one frame, multiple frames)
- The new “parallel structured light” technology
This article will discuss the basic differences between these techniques. Then it will focus on one major aspect they all struggle with, none of them being able to address it satisfactorily – except for one. This aspect is the high-quality data capture of scenes in motion. There is one single, novel technology that enables the snapshot area scanning of fast-moving objects at high quality, thus eliminating the need to compromise between quality and speed. This method is covered at the end of this article. But let’s go step by step.
Time-of-flight (ToF)
ToF systems are based on measuring the time during which a light signal emitted from the light source hits the scanned object and returns back to the sensor. While the scanning speed is relatively high, the limitation is the speed of light itself. Even a small error in the calculation of the moment of light incidence can result in a measurement error ranging from millimeters up to centimeters. Another limitation is that these sensors provide relatively low resolution.
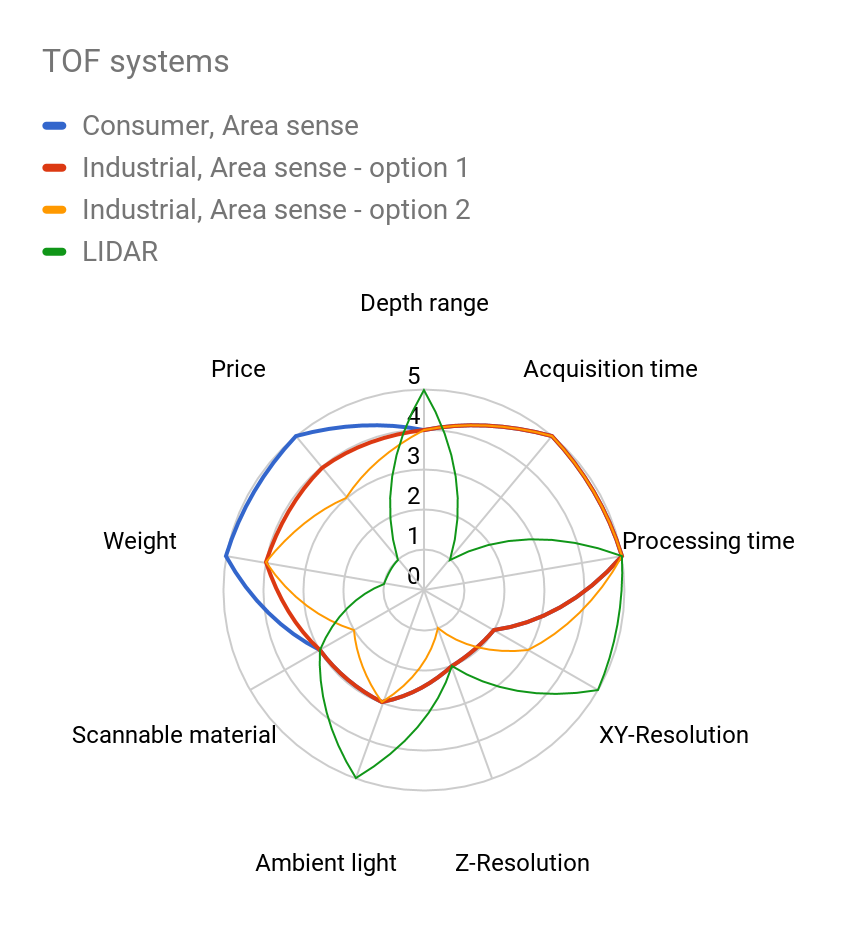
There are two distinctive techniques using the ToF approach – LiDAR and area sensing.
LiDAR
LiDAR systems sample one (or a few) 3D points at a time. During scanning, they change the position or orientation of the sensor to scan the whole operating volume.
ToF area sensing
ToF systems based on area sensing use a special image sensor to measure time for multiple measurements in a 2D snapshot. They do not provide such a high data quality as LiDAR systems but they are well suited for dynamic applications that suffice with a low resolution. One particular drawback of this method are interreflections between the parts of the scene, which can cause wrong measurements.
ToF systems are rather popular because of the attractive price of consumer devices primarily designed for human-computer interaction.
Triangulation-based methods
Triangulation-based systems observe scenes from two perspectives, which form a baseline. The baseline and the inspected point form a triangle – by measuring the angles of this triangle, we can compute the exact 3D coordinates. The length of the baseline and the accuracy of retrieving the angles strongly affect a system’s precision.
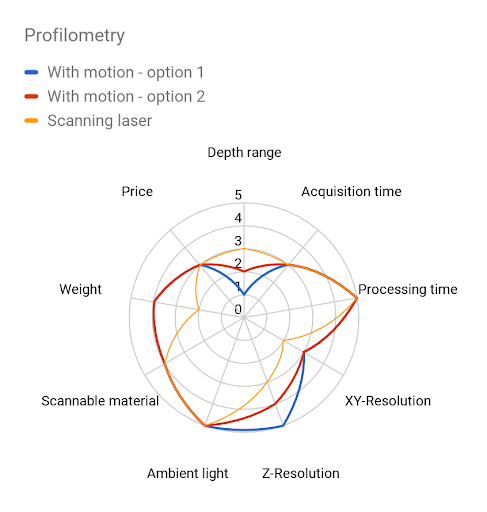
Laser triangulation = Profilometry
Laser triangulation is one of the most popular 3D sensing methods. It projects a narrow band of light (or a point) onto a 3D surface, which produces a line of illumination that will appear distorted from an angle other than that of the projector. This deviation encodes depth information.
Because it captures one profile at a time, either the sensor or the object needs to move, or the laser profile needs to scan through the scene, to make a whole snapshot.
In order to reconstruct depth for a single profile, this method requires the capture of a narrow area scan image, whereby its size limits the frame rate and consequently also the scanning speed. In addition, the depth calculation may get rather complicated as it relies on finding intensity maximas in captured 2D images, which is alone a complex problem.
Photogrammetry
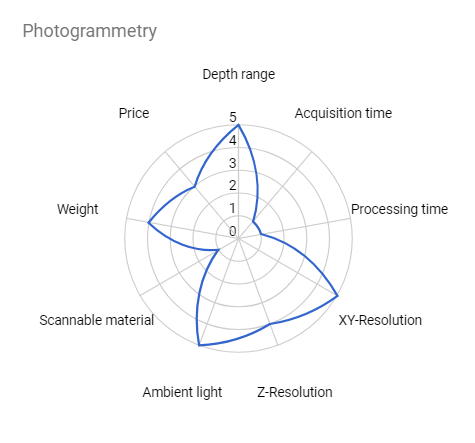
Photogrammetry is a technique that calculates the 3D reconstruction of an object from a high number of unregistered 2D images. Similarly to stereo vision, it relies on the object’s texture but it can benefit from multiple samples of the same point with a high baseline. Photogrammetry can be used as an alternative to LiDAR systems.
Stereo vision
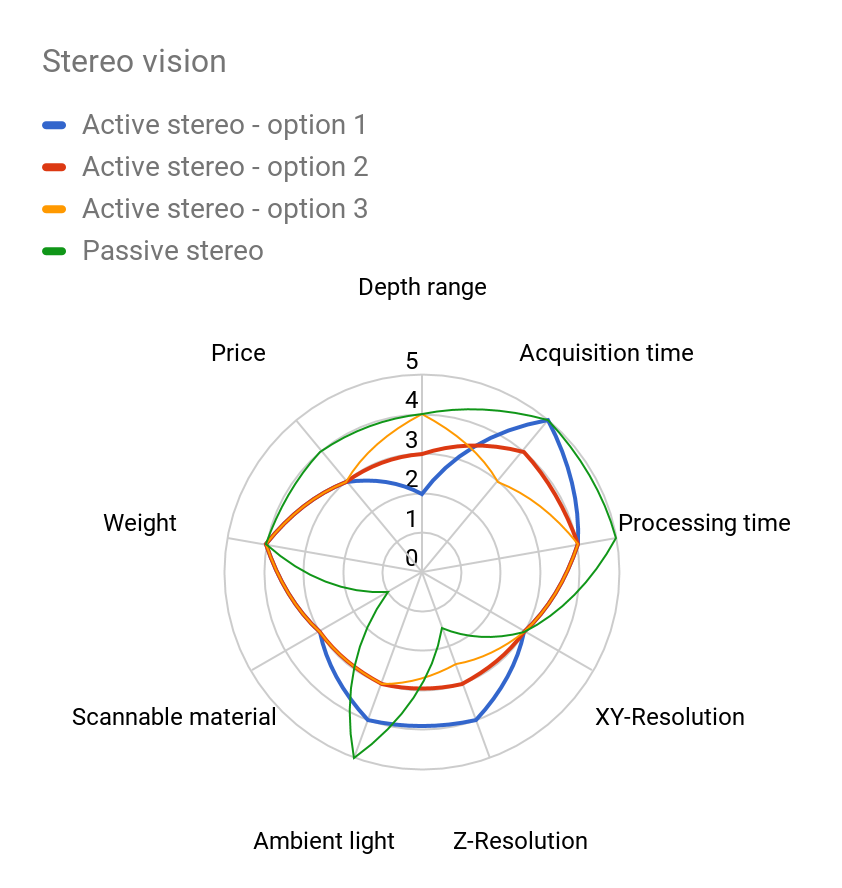
Stereo vision is based on the calculation of the triangle: camera – scanned object – camera, imitating the human depth perception.
The standard stereo looks for correlations between two images (they need to have a texture/identical details) and based on the disparity, it identifies the distance (depth) from the object. Because of this dependency on an object’s material, passive 3D stereo is used for applications that do not measure anything, such as counting people.
To compensate for this disadvantage, an active stereo vision system was developed. This method projects a light pattern onto the surface to create an artificial texture on the surface and correspondences in the scene. However, the identification of correspondences and measurement of one single depth point requires several neighbouring pixels, which results in a low number of measured points with generally lower robustness.
The depth calculation is based on an analysis of correspondences between the pair of stereo images, the complexity of which increases with the size of the matching window and the depth range. In order to meet strict processing time requirements, the reconstruction quality gets often compromised, which makes the method insufficient for certain applications.
Structured light
Another method that also belongs to triangulation approaches illuminates the scanned object with a so-called structured light. The triangle spans between a projector, the scanned object, and a camera. Because this method enables capturing the whole 3D snapshot of a scene without the need of moving any parts, the structured light technology provides a high-level of performance and flexibility.
Sophisticated projection techniques are used to create a coded structured pattern that encodes 3D information directly in the scene. This information is then analyzed by the camera and internal algorithms, providing a high level of accuracy and resolution.
Higher-resolution structured light systems available on the market use multiple frames of the scene, each with a different projected structured pattern. This ensures a high-accuracy per-pixel 3D information but requires a static scene at the moment of acquisition.
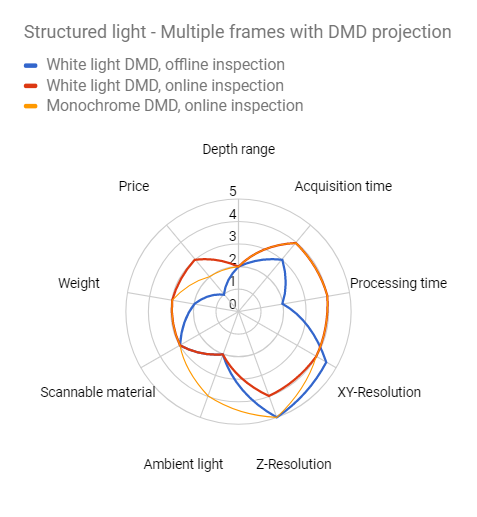
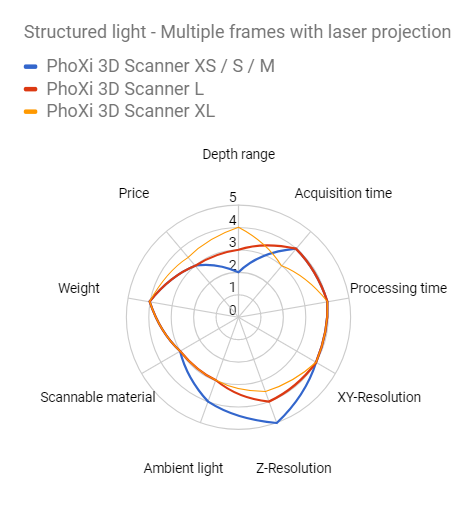
One of the biggest drawbacks of projection-based approaches is the depth of field (or depth range). To keep the projector focused, the system needs a narrow aperture. This is not optically efficient, as the blocked light creates additional heat and internal reflections in the projection system. This limits the use of this technology for higher depth ranges.
Photoneo solved this problem with a laser that creates structured patterns. Photoneo systems provide nearly unlimited depth range, and also the possibility to use narrow bandpass filters to block out ambient light.
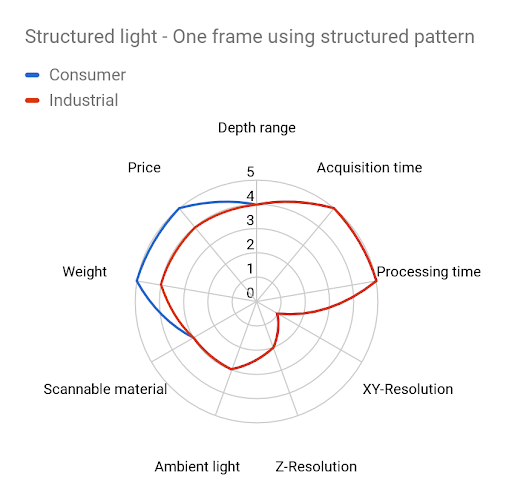
For a moving application, a one-frame approach needs to be used. A conventional technique is to encode distinctive features of multi-frame systems into one structured pattern, with strong impact on XY and Z resolution. Similar to ToF systems, there are consumer-based products available in this category.
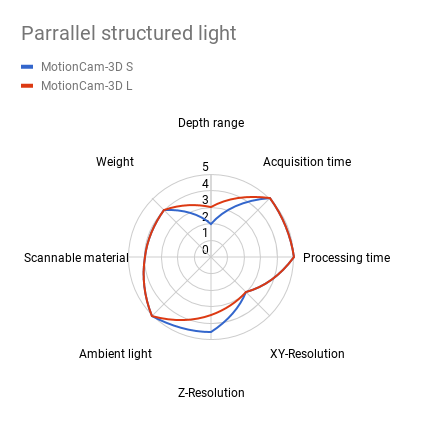
Parallel Structured Light
There is only one method that is able to overcome the limitations of scanning moving scenes.
The novel, patented technology named Parallel Structured Light was developed by Photoneo and allows the capture of objects in motion at high quality. The method uses structured light in combination with a proprietary mosaic shutter CMOS image sensor.
While the structured light method captures projector-encoded patterns sequentially, the Parallel Structured Light technology captures multiple images of structured light in parallel – this is the game-changing factor. Because the image acquisition of a 3D surface requires multiple frames, the output of scanning a moving object with the structured light method would be distorted. The Parallel Structured Light technology captures a dynamic scene by reconstructing its 3D image from one single shot of the sensor.
The special sensor consists of super-pixel blocks that are further divided into subpixels. The laser coming from a structured light projector is on the entire time, while exposures of the individual pixels are turned on and off in an encoded manner. This way there is one projection and one captured image – but this image contains multiple sub-images, each virtually illuminated by a different light pattern.
The result is very similar to that of multiple images over time, with the difference that this new method acquires them simultaneously = that’s why “Parallel Structured Light”. Another advantage of this technique is the possibility to switch the sensor into sequential mode and get a full 2MP resolution with metrology-grade quality.
The Parallel Structured Light technology thus offers the high resolution of multiple-frame structured light systems and fast, one-frame acquisition of ToF systems.
Photoneo implemented this technology into its 3D camera MotionCam-3D, thus developing the highest-resolution and highest-accuracy area scan 3D camera that is able to capture objects in motion.
Conclusion
This article presented a plurality of 3D vision methods and explained their specific advantages and weak points. Most of the state-of-the-art 3D methods make a compromise between quality and speed, either because of a demanding acquisition process or complex data processing. The only technology that delivers both quality and speed simultaneously is the Parallel Structured Light based on Photoneo original CMOS sensor. This new method expands the range of possible applications and enables automation where it was not possible before.


