
The power of AI in industrial automation
The most advanced approaches to fully intelligent robotic systems
AI (artificial intelligence) enables the automation of a growing number of business processes and industrial applications. The scope and pace of smart automation are directly dependent on the advancements in AI and as such have experienced giant leaps forward in recent years. Combined with powerful 3D machine vision, AI enables robots to recognize, localize, and handle any type of object and thus automate tasks that would be too dangerous, monotonous, or otherwise demanding for humans.

But what is meant by AI in industrial automation, how does it work, and what possibilities does it open to factories and businesses striving for modernity, innovation, and increased productivity? First of all, let’s have a look at the very beginnings of AI and its gradual development.
From the first architectures to convolutional neural networks
The term AI may represent a number of machine capabilities and processes – from simple statistics through decision trees up to neural networks, such as convolutional neural networks, or even more advanced approaches such as reinforcement learning.
The history of the development of AI witnessed several approaches but neural networks proved to be the most promising and interesting thanks to their ability to generalize.
In the 1990s and early 2000s, neural networks received great attention thanks to the first successful applications of character recognition that included the reading of handwritten numbers in bank checks and letter zipcodes. These neural networks were trained on a so-called MNIST dataset (standing for Modified National Institute of Standards and Technology), which is a collection of handwritten digits from 0 to 9 used in machine learning and machine vision for training image processing systems. MNIST dataset served as the basis for benchmarking classification algorithms and is still used today for training and testing purposes.

Though these classical neural networks are able to learn practically anything, they represent an old, fully-connected architecture and training them requires a lot of time and effort. This is because all neurons in one layer are fully connected to the neurons in the next layer – which means a huge number of parameters to learn, rising with the size of an image. Though the performance of computers improved over time, it still takes very long to train the recognition of even small images.
A turning point in the development of AI was marked by the introduction of convolutional neural networks (CNNs). CNNs are mainly used for analyzing visual imagery, including image classification or pattern recognition, and form the backbone of many modern machine vision systems. Another main field of application is natural language processing.
A CNN is, very loosely speaking, inspired by the visual cortex system in the brain. The main idea behind CNNs is not to connect all neurons with one another, as is the case with fully connected networks, but only with neighboring neurons to create proximity, since neighboring inputs, such as pixels, carry related information. This means that CNNs can have several layers and neurons in one layer are only connected to neurons in the next layer that are spatially close to them. This reduces complexity, the number of neurons in the network, and consequently also the number of parameters to learn. Thanks to this, CNNs are faster to train, need fewer samples, and can also be applied to larger images.
The term “convolutional” refers to the filtering process through which CNNs detect patterns. The individual layers convolve, i.e. combine, the input and pass the result to the next layer.
The progress in the development of CNNs has also been accelerated by the advancements in graphics processing units (GPUs). Their performance and calculation power have improved immensely over the past few years, opening up new possibilities for training CNNs.
One of the most recognized leaders in the field of AI, often referred to as the “Godfather of AI”, is Geoffrey Hinton. He has a degree in experimental psychology and artificial intelligence. This combination gave him great insight into how to train artificial neural networks.
In 2012 his student Alex Krizhevsky marked another turning point in AI when he created a CNN that was able to mimic the way the human brain recognizes objects. The CNN was named the AlexNet and for the first time in history enabled a machine to identify objects like a person.
This breakthrough popularized convolutional neural networks and showed the huge range of applications where CNNs could be used.
Training a convolutional neural network
In object recognition, it is important that a CNN has a property called invariance. This means that it is invariant to translation, viewpoint, size, or illumination to be able to interpret input patterns and classify objects regardless of where and how they are placed in an image. To achieve this, CNN needs to be trained on a certain amount of examples. One of the best practices to increase the amount of relevant data in a dataset is data augmentation.
Augmentation is the practice of modifying input data, i.e. the original image, to generate several other, slightly altered versions of it. Augmentation techniques include horizontal or vertical flipping, rotation, scaling, cropping, moving the image along the X or Y direction, and others.
Training a CNN on an altered data makes its neurons immune to such augmentations and prevents it from learning irrelevant patterns. A flipped parrot will thus still be recognized as a parrot.
What comes very handy here is so-called transfer learning. To eliminate the amount of training data, one can use an existing and already trained network and apply some of its filters for the recognition of new kinds of objects. For instance, a network trained for the recognition of dogs can also be used for the recognition of cats by keeping some of its filters and modifying only a certain part of it. This means that the network will adapt to the recognition of cats.
Benefits of modular convolutional neural networks
The great value of CNNs lies in their architecture and the fact that the individual modules look at single image blocks. The modules do not need to be trained simultaneously and can be easily joined together. Combining these well-trained modules gave rise to complex architectures that can be used for segmentation.
In contrast to the AlexNet, which can only recognize what is in the image, these complex CNNs can do object segmentation and define the object’s location in the image.
This modularity enables one to use various input channels, which means that if the CNN was used for black & white data, it can also be used for color data, and if it was used for color data, it can be extended by depth information. Adding additional information boosts the CNN’s performance, which includes increased accuracy and better recognition of objects and their positions.
From object recognition to smart automation solutions
Based on the above features and characteristics of convolutional neural networks, Photoneo took CNNs as a basis for its advanced robotic intelligence systems and automation solutions.
Photoneo’s CNN works with black & white data, color data, as well as depth information. The algorithms are trained on a large dataset of objects and if they come across new types of items, they can quickly generalize, that is, recognize and classify objects which it has not “seen” before.
Let’s take the concept of a box, for instance. The algorithms were trained on a large dataset of boxes so they understand that a box has a certain amount of faces, edges, and vertices. This principle will also work for boxes that the algorithms have not come across before, even squeezed or damaged ones. The greatest value of AI lies in the fact that it can generalize concepts that it was trained on without further retraining.

This enables Photoneo systems to recognize items of various shapes, sizes, colors, or materials – a robotic ability used for the localization and handling of mixed objects, including organic items such as fruit or fish, sorting of parcels, unloading of pallets laden with boxes, and many other industrial applications.

It might also happen that the algorithms come across objects with features that are fundamentally different from those the algorithms were trained on. This might confuse the CNN and cause a decrease in its performance. What can be done to solve this problem is either to prevent it by expecting exotic objects or to have a good retraining system. In the latter case, the performance will be temporarily lower but the CNN will be retrained to reach full performance rather quickly.
In case a customer needs to pick unusual items or non-commercial products such as industrial components, the CNN can be trained on a specific dataset containing these exotic items.
When it comes to the realization of a customer project, the customer receives Photoneo’s CNN for pilot testing and a feasibility study to ensure that the network can be used for that particular application. This CNN can then be improved and further trained on images from the pilot phase of the project, which will provide greater variability.
The greatest challenge in AI-powered object recognition and picking
The greatest challenge could also be described as the last puzzle piece that was missing in the range of pickable objects. This last piece was bags.
The difficulty lies in the nature of bags since they are extremely deformable and full of wrinkles, folds, and other irregularities. Despite the challenges that bags pose to AI, Photoneo developed a system that is able to recognize and pick bags, may they be full, half-empty, colored, transparent, or semi-transparent. This task is often challenging even for the human eye, which may find it difficult to recognize boundaries between bags that are chaotically placed in a container, especially if they are transparent.
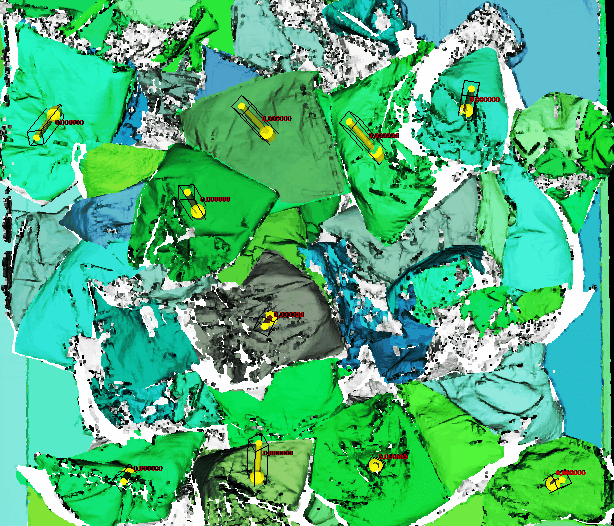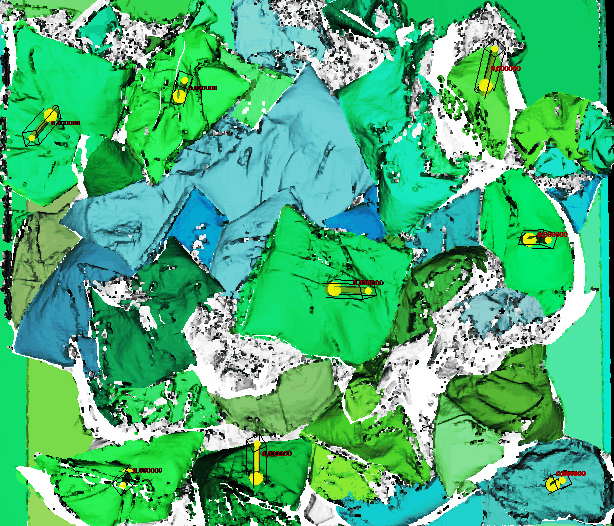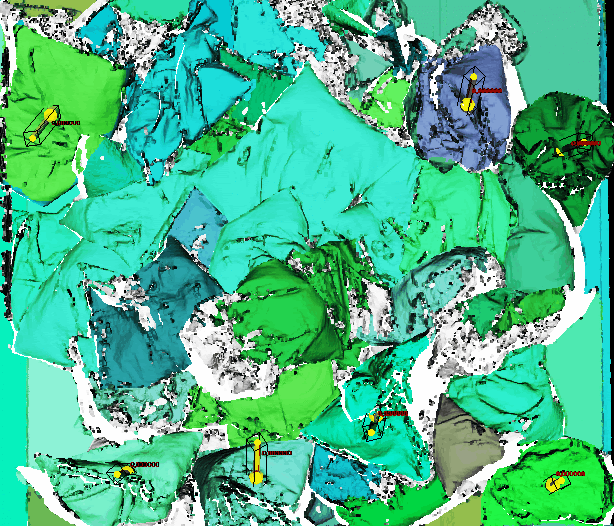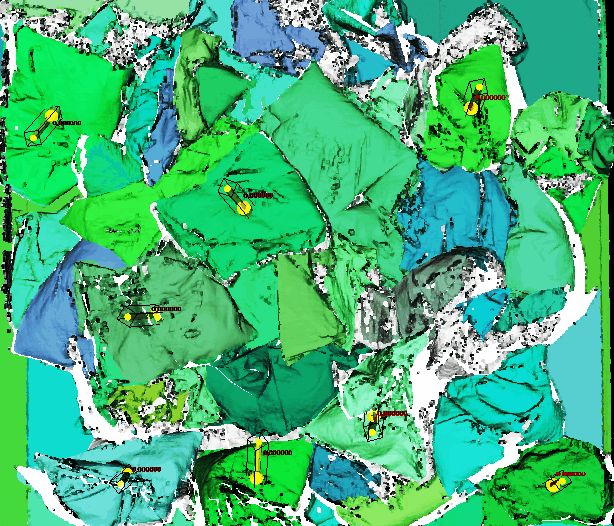
However, good recognition and localization of bags are only part of the precondition for successful object picking. The other part relates to the mechanical side of an application – the robot gripper. The fact that bags are full of folds and wrinkles increases the risk that they will fall off the gripper. This risk can be prevented by using an appropriate vacuum gripper with feedback.
Future developments of AI
Despite significant advancements that have been made in AI in recent years, the field still offers a vast space for new achievements. For instance, so-called reinforcement learning receives great attention as it seems to be very promising in suggesting complex movements, for instance allowing a robot to adjust the position of an item before grasping it.
Reinforcement learning is not only able to cope with object recognition but also with mechanical problems of an application. This means that it not only enables a system to recognize items but also assess the individual steps of a robot action on the basis of rewards and punishments and “calculate” the chance of success or failure. In other words, AI algorithms are trained to make a sequence of decisions that will lead to actions maximizing the total reward. An example of the power of reinforcement learning is mastering and winning the board game of Go.
Despite its immense potential, reinforcement learning is closely linked to the environment it is set in and to the limitations it may pose. For example, the deployed gripper and its functionalities and limitations will always influence a system’s overall performance.
AI is the main driver of emerging technologies and its developments will be very dependent on a number of factors, including market demands, customer expectations, competition, and many others.


